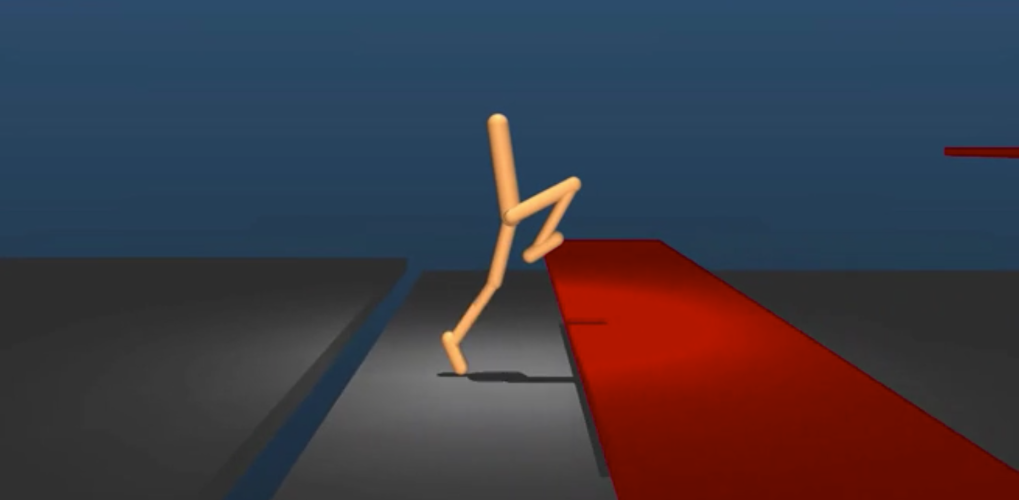
加强学习(RL)是通过使用奖励制度来教导和指导行为的做法。理想行为产生奖励; 不良行为不行。它是机器学习中常用的工具,现在字母表团队已经用它来教导DeepMind AI成功导航跑酷课程。
团队希望看到简单的回报是否能在复杂的环境中工作。他们建立了一个虚拟的跑步课程,有滴,障碍和俯卧撑,并为进步取得了积极的回报。在最基本的层面上,系统如下:AI移动越过地形越快,奖励就越大。为更复杂的计划增加了额外的激励和惩罚。
代理在跑酷中玩乐!来自DeepMind的同事的酷文https://t.co/X0PwKXrQ2M?ncid=txtlnkusaolp00000618pic.twitter.com/yMT6XCNv45
- Oriol Vinyals(@OriolVinyalsML)2017年7月10日
您可以在此视频中看到完整的结果; 所有的棒状图的导航都是通过强化学习教导的。AI使用一个试错系统来确定如何尽快向前移动,而不会“终止”。
很明显,DeepMind正在使用创造性的解决方案来克服所提供的障碍; 大多数时候,提供最有效解决方案的运动并不完全是自然而然的。它为未来的AI提供了有趣的可能性,因为机器人实际上不必将自己限制在人类的运动中,以达到设定的目标。看看这是否会对未来的AI和机器人开发产生影响,这将是有趣的。















塞拉利昂泥石流:至少600人失踪在弗里敦
图像版权路透图片标题山坡上许多房子倒塌大雨后摄政 至少有600人失踪后泥石流和洪水摧
便士响应特朗普的话:“我站在总统身边”
副总统便士周三表示,他在总统特朗普的批评下表示赞成,他的言论指责了在白俄罗斯的夏
布里吉特・Macron证实,“宪章”会澄清其作用透明度
布里吉特Macron采访中证实,它将在星期五杂志,它的作用将是非依据一项法律,而是章程,阐
夏洛特维尔受害者的妈妈到白人至上主义者:“你只是放大她的”
在星期三举行的仪式上,希瑟海耶(Heather Heyer)是一名32岁的受害者的母亲苏珊布罗
Nathan取缔最佳英国餐厅美食指南
康沃尔郡的海鲜餐馆已经加冕最好的在英国每年食物指南,肘击坎布里亚郡L Enclume后到了